366 将字符串c中得多字节字符转化成等价的单字节字符。该函数仅当数据库字符集同时包含单字节和多字节字符时才使用 将字符串c中得多字节字符转化成等价的单字节字符。该函数仅当数据库字符集同时包含单字节和多字节字符时才使用
367
368 其它单行函数
369
370 BFILENAME(
371,)
372 dir是一个directory类型的对象,file为一文件名。函数返回一个空的BFILE位置值指示符,函数用于初始化BFILE变量或者是BFILE列。
373
374 DECODE(,,[,,,[])
375 x是一个表达式,m1是一个匹配表达式,x与m1比较,如果m1等于x,那么返回r1,否则,x与m2比较,依次类推m3,m4,m5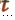 .直到有返回结果。 .直到有返回结果。
376
377 DUMP(,[,[,[,]]])
378 x是一个表达式或字符,fmt表示8进制、10进制、16进制、或则单字符。函数返回包含了有关x的内部表示信息的VARCHAR2类型的值。如果指定了n1,n2那么从n1开始的长度为n2的字节将被返回。
379
380 EMPTY_BLOB()
381 该函数没有参数,函数返回 一个空的BLOB位置指示符。函数用于初始化一个BLOB变量或BLOB列。
382
383 EMPTY_CLOB()
384 该函数没有参数,函数返回 一个空的CLOB位置指示符。函数用于初始化一个CLOB变量或CLOB列。
385
386 GREATEST()
387 exp_list是一列表达式,返回其中最大的表达式,每个表达式都被隐含的转换第一个表达式的数据类型,如果第一个表达式是字符串数据类型中的任何一个,那么返回的结果是varchar2数据类型, 同时使用的比较是非填充空格类型的比较。
388
389 LEAST()
390 exp_list是一列表达式,返回其中最小的表达式,每个表达式都被隐含的转换第一个表达式的数据类型,如果第一个表达式是字符串数据类型中的任何一个,将返回的结果是varchar2数据类型, 同时使用的比较是非填充空格类型的比较。
391
392 UID
393 该函数没有参数,返回唯一标示当前数据库用户的整数。
394
395 USER
396 返回当前用户的用户名
397
398 USERENV()
399 基于opt返回包含当前会话信息。opt的可选值为:
400
401 ISDBA 会话中SYSDBA脚色响应,返回TRUE
402 SESSIONID 返回审计会话标示符
403 ENTRYID 返回可用的审计项标示符
404 INSTANCE 在会话连接后,返回实例标示符。该值只用于运行Parallel 服务器并且有 多个实例的情况下使用。
405 LANGUAGE 返回语言、地域、数据库设置的字符集。
406 LANG 返回语言名称的ISO缩写。
407 TERMINAL 为当前会话使用的终端或计算机返回操作系统的标示符。
408
409 VSIZE()
410 x是一个表达式。返回x内部表示的字节数。
411
412 SQL中的组函数
413
414 组函数也叫集合函数,返回基于多个行的单一结果,行的准确数量无法确定,除非查询被执行并且所有的结果都被包含在内。与单行函数不同的是,在解析时所有的行都是已知的。由于这种差别使组函数与单行函数有在要求和行为上有微小的差异.
415
416 组(多行)函数
417
418 与单行函数相比,oracle提供了丰富的基于组的,多行的函数。这些函数可以在select或select的having子句中使用,当用于select子串时常常都和GROUP BY一起使用。
419
420 AVG([{DISYINCT|ALL}])
421 返回数值的平均值。缺省设置为ALL.
422
423SELECT AVG(sal),AVG(ALL sal),AVG(DISTINCT sal) FROM scott.emp
424
425AVG(SAL) AVG(ALL SAL) AVG(DISTINCT SAL)
426
4271877.94118 1877.94118 1916.071413
428
429
430 COUNT({*|DISTINCT|ALL} )
431 返回查询中行的数目,缺省设置是ALL,*表示返回所有的行。
432
433 MAX([{DISTINCT|ALL}])
434 返回选择列表项目的最大值,如果x是字符串数据类型,他返回一个VARCHAR2数据类型,如果X是一个DATA数据类型,返回一个日期,如果X是numeric数据类型,返回一个数字。注意distinct和all不起作用,应为最大值与这两种设置是相同的。
435
436 MIN([{DISTINCT|ALL}])
437 返回选择列表项目的最小值。
438
439 STDDEV([{DISTINCT|ALL}])
440 返回选者的列表项目的标准差,所谓标准差是方差的平方根。
441
442 SUM([{DISTINCT|ALL}])
443 返回选择列表项目的数值的总和。
444
445 VARIANCE([{DISTINCT|ALL}])
446 返回选择列表项目的统计方差。
447
448 用GROUP BY给数据分组
449
450 正如题目暗示的那样组函数就是操作那些已经分好组的数据,我们告诉数据库用GROUP BY怎样给数据分组或者分类,当我们在SELECT语句的SELECT子句中使用组函数时,我们必须把为分组或非常数列放置在GROUP BY子句中,如果没有用group by进行专门处理,那么缺省的分类是将整个结果设为一类。
451
452select stat,counter(*) zip_count from zip_codes GROUP&nbs上一页 [1] [2] [3] [4] [5] [6] 下一页 |




