作者:木艺儿
搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。但是,如果网站的某些信息不想被别人搜索到,可以创建一个纯文本文件robots.txt,放在网站根目录下。这样,搜索机器人会根据这个文件的内容,来确定哪些是允许搜寻的,哪些是不想被看到的。
有趣的是,这种特性往往用来作为参考资料,猜测网站又有什么新动向上马,而不想让别人知道。例如通过分析Google的robots.txt变化来预测Google将要推出何种服务。
有兴趣的读者可以看一下Google的robots.txt文件,注意到前几行就有“Disallow: /search”,而结尾新加上了“Disallow: /base/s2”。
现在来做个测试,按照规则它所隐藏的地址是http://www.Google.com/base/s2,打开之后发现Google给出了一个错误提示:“服务器遇到一个暂时性问题不能响应您的请求,请30秒后再试。”
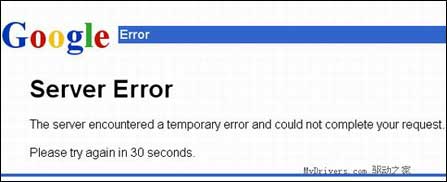
图1
但是把s2最后的数字换成1、3或者别的什么数字的时候,错误提示又是另一个样子:“我们不知道您为什么要访问一个不存在的页面。”
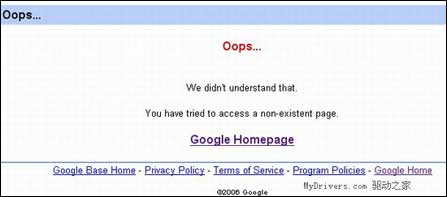
图2
很显然“/base/s2”是一个特殊的页面,鉴于Google曾表示过今年的主要焦点是搜索引擎,我们推测一下,所谓的“s2”是否表示“search2”,也就是传说中的第二代搜索引擎?
| 



