Author: Henry Chen 译者:李力
介绍
由于可扩展标记语言(XML)的易用性和轻携性,其近年来获得了极大的流行。它与Java结合起来,非常适用于可移植的数据和代码。每一个与XML文档打交道的Java程序员,无论是读数据,还是进行数据转换,都必须对Java API’s for XML Processing (JAXP)有一个很深的理解。编写XML解析器无关的代码有许多好处,JAXP API 是用于XML的,就像JDBC API是用于关系型数据库的。这篇介绍性的文章帮助开发者学习JAXP API,并让开发者对可插入层(pluggability layer)有一个很深的理解,这样,开发者就可以在他们的应用程序中自如的更换解析器。
JAXPack
SUN推出了一个用于XML的Java API 和架构,称其为Java XML Pack (JAXPack - http://java.sun.com/xml/javaxmlpack.html)。下载包中包括了现在行业中一些重要的标准。这篇文章中,我们将注意力放在JAXP(the API for XML Processing)上,Sybase的Easerver从版本3.6.1开始支持JAXP。
首先,我们看一下JAXP提供的解析能力,解析XML文档有两种最基本的方法, 基于事件的SAX和遍历树的DOM。开发者可以选择最适合他们需要的方法。让我们钻进去,深入的看一下这些API。
这篇文章中,我们用图1中的XML文档来阐述我们的例子。

SAX
Simple API for XML Parsing (SAX)是事件驱动的,它从头到尾遍历整个文档, 当它遇到一个语法结构时,它会通知运行它的程序,这些是通过事件处理接口ContentHandler, ErrorHandler, DTDHandler, 和 EntityResolver中的回调方法实现的。这些回调方法可以被开发者自定义实现来满足一些特殊的要求。图2描绘了SAX解析器解析文档是各种组件之间的关系。
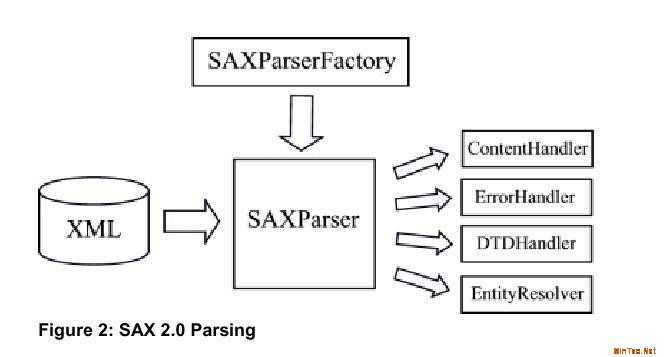
我们将遍历图1中XML文档,并且给出SAX解析器一行一行的解析是调用回调方法的细节,在这个例子中,我们不包括对ignorableWhiteSpace方法调用。

现在你已经对SAX如何工作有一个总体的了解,接下来,让我们看一看用真真的Java代码实现的例子,我们实现的程序的完整代码可以在http://www.sybase.com/developer.上找到,出于这篇文章的目的,我将只用一些代码相关部分的片断。
-
- public class SAXExample extends DefaultHandler {
- SAXParserFactory factory = SAXParserFactory.newInstance();
- SAXParser saxParser = factory.newSAXParser();
-
- DefaultHandler handler = new SAXExample();
- saxParser.parse( new File(argv[0]), handler)
注意我们继承了DefaultHandler Class, 这个类用一些空方法实现了ContentHandler, ErrorHandle, DTDHandler,和 EntityResolver接口,这样,程序员就可以只覆盖一些他们需要的方法。
在我们解析之前,我们首先需要通过调用newInstance方法,实例化一个SAXParserFactory,这个方法用某个特定的查找顺序来决定使用哪一个SAXParserFactory的实现,这就意味着,解析器更改时,代码无需重新编译。
一旦我们实例化了一个SAXParserFactory,我们可以设置三个选项,这些决定了随后如何产生SAXParser的对象。
SAXParserFactory 使namespace可用
SetValidating 打开验证
SetFeature 设定底层实现的特征
SAXParserFactory配置好后,我们调用newSAXParser方法来实例化一个JAXP SAXParser对象,这个对象包装了一个底层的SAX解析器,并且允许我们以厂商中立的方式与其交互,现在,我们就可以解析了。在这个例子中,我们用File对象作为输入,它还可以接受其他的输入源,如InputSource对象,InputStream 对象,或者Uniform Resource Identifier (URI)。
注意程序是如何使自己成为解析器的处理者(handler)的,这意味着解析器将调用SAXExampl中的回调方法的,当解析方法一行一行的解析XML文件时,我们的处理类中的回调事件就发生了。
DOM
Document Object Model (DOM)是将XML文档解析成树状对象的一套接口,每一个对象,或结点(node)都有一个用org.w3c.dom包中的接口表示的类型(type).如Element, Attribute,
Comment, 和Text。可以像操作其他任何树状数据结构一样来操作DOM树状对象,它允许随机访问XML文档中特定部分的数据,并且修改它,这些是SAX解析器做不到的。
这种方法的缺点是它非常占用内存和CPU资源,因为构建DOM树时需要将整个XML文档读入并保持在内存中。
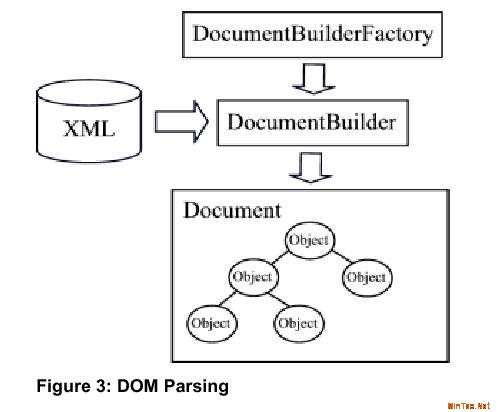
让我们看一个例子:
-
- public class DOMExample {
- DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- DocumentBuilder domParser = factory.newDocumentBuilder();
- Document document = domParser.parse( new File(argv[0]) );
.
与SAX类似,我们首先用newInstance方法实例化一个DocumentBuilderFactory对象,同样类似SAXParserFactory,工厂可以配置用来处理namespace(命名空间)和validation(验证)。另外,还有一些其他可选的设置,但这已经超出了本文的范围。工厂对象准备好后,我们就可以创造一个DocumentBuilder对象,它可用来解析xml文件和创造Document对象,同样类似SAXParser的parse方法,Document对象可以接受InputSource对象,InputStream对象,或者URI。
-
- Node thePhonebook = document.getDocumentElement();
- NodeList personList = thePhonebook.getChildNodes();
-
- Node currPerson = personList.item(0);
- Node fullName = currPerson.getChildNodes().item(0);
- Node firstName = fullName.getChildNodes().item(0);
- Node lastName = fullName.getChildNodes().item(1);
- Text firstNameText = (Text)firstName.getFirstChild();
- Text lastNameText = (Text)lastName.getFirstChild();
-
- Node phone = currPerson.getChildNodes().item(1);
- Node workPhone = phone.getChildNodes().item(0);
- Node homePhone = phone.getChildNodes().item(1);
- Text workPhoneText = (Text)workPhone.getFirstChild();
- Text homePhoneText = (Text)homePhone.getFirstChild();
一旦我们拥有了Document DOM对象,我们就可以像操作其他树一样操作它。getDocumentElement方法返回根元素,从根元素可以得到子节点的NodeList,并且可以处理它们。在DOM树结构的叶结点,我们可以找到Text对象,它继承了Node。调用getData方法可以返回字符串的值。如你所见,使用者在操作数据时必须对文档数据的结构有一个了解,而在SAX中,解析器仅仅对它遇到的数据反应。
但是,DOM最大的优点是它可以对数据结构进行修改,例如:
-
- if (firstNameText.getData().equals("Richard") &&
- lastNameText.getData().equals("Mullins")) {
- homePhoneText.setNodeValue("(510)333-3333");
- }
用setNodeValue方法可以改变DOM树中的数据,随后,我们将看XSLT如何将一个新树写入一个数据文件。
XSLT
XSL转换(XSLT)是将XML文档转换为其他XML文档或其他格式的文档(如HTML)的一组API, XML样式语言(XSL)在转换中作用巨大,用其定义的样式表包含了格式规则,指定了文档如何显示。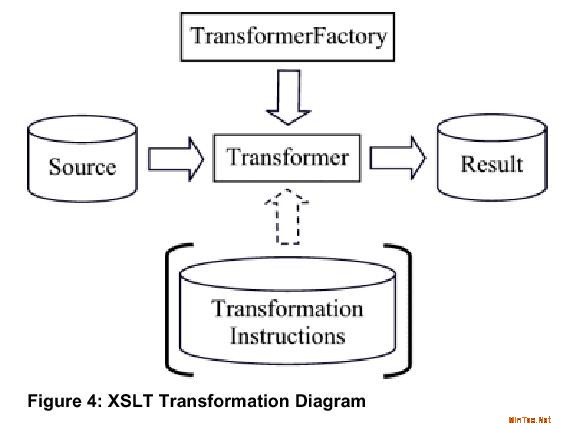
这里有一个例子,将DOM对象转换为XML文档:
-
- //create a new DOMSource using the root node of an existing DOM tree
- DOMSource source = new DOMSource(thePhonebook);
- StreamResult result = new StreamResult(System.out);
-
- TransformerFactory tFactory = TransformerFactory.newInstance();
- Transformer transformer = tFactory.newTransformer();
- transformer.transform(source, result);
我们首先用newI[1] [2] 下一页 |




