它跟在被检索的行计数的后面, 该计数通过调用mysql_num_rows() 来计算。像mysql_ affected_rows() 一样,mysql_num_rows() 返回my_ulonglong 值,因此,将值转换为
unsigned long 型,并用‘% l u’ 格式打印。
提取行的循环紧接在一个错误检验的后面,如果要用mysql_store_result() 创建结果集,
mysql_fetch_row() 返回的NULL值通常意味着“不再有行”。然而,如果用mysql_ use _ result( )创建结果集,则mysql_fetch_row() 返回的NULL 值通常意味着“不再有行”或者发生了错误。无论怎样创建结果集,这个测试只允许process_result_set() 检测错误。
process_result_set() 的这个版本是打印列值要求条件最低的方法,每种方法都有一定的缺点,例如假设执行下面的查询:
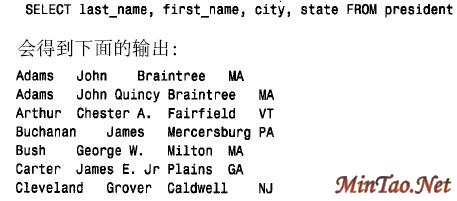
我们可以通过提供一些信息如列标签,及通过使这些值垂直排列,而使输出结果漂亮一点。为此,我们需要标签和每列所需的最宽的值。这个信息是有效的,但不是列数据值的一部分,而是结果集的元数据的一部分(有关数据的数据)。简单归纳了一下查询处理程序后,我们将在6 . 6 . 6节“使用结果集元数据”中给出较漂亮的显示格式。
打印二进制数据
对包含可能含有空字节的二进制数据的列值,使用‘ % s’printf() 格式标识符不能将它正确地打印; printf() 希望一个空终结串,并且直到第一个空字节才打印列值。对于二进制数据,最好用列的长度,以便打印完整的值,如可以用fwrite() 或putc( )。
6.6.3 通用目标查询处理程序
前面介绍的处理查询样例应用了语句是否应该返回一些数据的知识来编写的。这是可能的,因为查询固定在代码内部:使用INSERT 语句时,它不返回结果,使用SHOW TABLES语句时,才返回结果。
然而,不可能始终知道查询用的是哪一种语句,例如,如果执行一个从键盘键入或来源于文件的查询,则它可能是任何的语句。不可能提前知道它是否会返回行。当然不想对查询做语法分析来决定它是哪类语句,总之,并不像看上去那样简单。只看第一个单词是不够的,因为查询也可能以注释语句开始,例如:
/* comment * / SELECT
幸运的是不必过早地知道查询类型就能够正确地处理它。用MySQLC API 可编写一个能很好地处理任何类型语句的通用目标查询处理程序,无论它是否会返回结果。在编写查询处理程序的代码之前,让我们简述一下它是如何工作的:
■ 发布查询,如果失败,则结束。
■ 如果查询成功,调用mysql_store_result() 从服务器检索行,并创建结果集。
■ 如果mysql_store_result() 失败,则查询不返回结果集,或者在检索这个结果集时发生错误。可以通过把连接处理程序传递到mysql_field_count() 中,并检测其值来区别这两种情况,如下:
■ 如果mysql_field_count() 非零,说明有错误,因为查询应该返回结果集,但却没有。这种情况发生有多种原因。例如:结果集可能太大,内存分配失败,或者在提取行时客户机和服务器之间发生网络中断。
这种过程稍微有点复杂之处就在于, MySQL3.22.24 之前的早期版本中不存在mysql_ field _ count( ),它们使用的是mysql_ num _ fields ( )。为编写MySQL任何版本都能运行的程序,在调用mysql_field_count() 的文件中都包含下面的代码块:

这就将对mysql_field_count() 的一些调用看作是比MySQL3.22.24 更早版本中的mysql_num_fields() 的调用。
■ 如果mysql_field_count() 返回0,就意味着查询不返回结果(这说明查询是类似于INSERT、DELETE、或UPDATE 的语句)。
■ 如果mysql_store_result() 成功,查询返回一个结果集,通过调用mysql_fetch_row() 来处理行,直到它返回NULL 为止。
下面的列表说明了处理任意查询的函数,给出了连接处理程序和空终结查询字符串:



6.6.4 可选择的查询处理方法
process_query() 的这个版本有三个特性:
■ 用mysql_query() 发布查询。
■ 用mysql_store_query() 检索结果集。
■ 没有得到结果集时,用mysql_field_count() 把错误事件和不需要的结果集区别开来。针对查询处理的这些特点,有如下三种方法:
■ 可以用计数查询字符串和mysql_ real _ query( ),而不使用空终结查询字符串和mysql_ query( )。
■ 可以通过调用mysql_use_result() 而不是调用mysql_store_result() 来创建结果集。
■ 可以调用mysql_error() 而不是调用mysql_field_count() 来确定结果集是检索失败还是仅仅没有设置检索。
可用以上部分或全部方法代替process _ query( )。以下是一个process_real_query() 函数,它与process_query() 类似,但使用了所有三种方法:


6.6.5 mysql_store_result() 与mysql_use_result() 的比较
函数mysql_store_result() 与mysql_use_result() 类似,它们都有连接处理程序参数,并返回结果集。但实际上两者间的区别还是很大的。两个函数之间首要的区别在于从服务器上检索结果集的行。当调用时, mysql_store_result() 立即检索所有的行,而mysql_use_result() 启动查询,但实际上并未获取任何行, mysql_store_result() 假设随后会调用mysql_ fetch _ row( )检索记录。这些行检索的不同方法引起两者在其他方面的不同。本节加以比较,以便了解如何选择最适合应用程序的方法。
当mysql_store_result() 从服务器上检索结果集时,就提取了行,并为之分配内存,存储到客户机中,随后调用mysql_fetch_row() 就再也不会返回错误,因为它仅仅是把行脱离了已经保留结果集的数据结构。mysql_fetch_row() 返回NULL 始终表示已经到达结果集的末端。相反,mysql_use_result() 本身不检索任何行,而只是启动一个逐行的检索,就是说必须对每行调用mysql_fetch_row() 来自己完成。既然如此,虽然正常情况下, mysql_ fetch _ row( )返回NULL 仍然表示此时已到达结果集的末端,但也可能表示在与服务器通信时发生错误。可通过调用mysql_errno() 和mysql_error() 将两者区分开来。
与mysql_use_result() 相比,mysql_store_result() 有着较高的内存和处理需求,因为是在客户机上维护整个结果集,所以内存分配和创建数据结构的耗费是非常巨大的,要冒着溢出内存的危险来检索大型结果集,如果想一次检索多个行,可用mysql_ use _result( )。mysql_use_result() 有着较低的内存需求,因为只需给每次处理的单行分配足够的空间。这样速度就较快,因为不必为结果集建立复杂的数据结构。另一方面, mysql_use_result() 把较大的负载加到了服务器上,它必须保留结果集中的行,直到客户机看起来适合检索所有的行。这就使某些类型的客户机程序不适用mysql_ use _ result( ):
■ 在用户的请求下提前逐行进行的交互式客户机程序(不必仅仅因为用户需要喝杯咖啡而让服务器等待发送下一行)。
■ 在行检索之间做了许多处理的客户机程序。在所有这些情况下,客户机程序都不能很快检索结果
|




