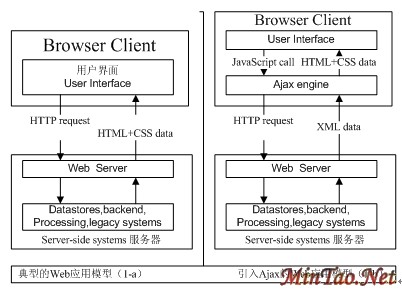
Model 2则解决了这些问题,它是面向对象的MVC模式(Model-View-Controller,模型-视图-控制器)在Web开发中的应用,Model表示应用的业务逻辑,View是应用的表示层页面,Controller是提供应用的处理过程控制。通过这种MVC设计模式把应用逻辑,处理过程和显示逻辑划分成不同的组件、模块实现,组件间可以进行交互和重用。
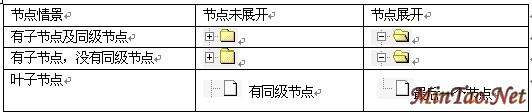
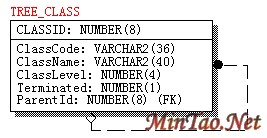
图 3 树型表结构示意图 树遍历的时间复杂度是O( n ),但是将树信息存放到数据库后,就不能按传统的方式遍历树,必须使用SQL 语句访问数据库表的内容,而一次性取的数据量越多,消耗的资源也越多,用户等待的时间就越长。如果将无序的数据从数据库中读出,在服务器端,必须将排序后的树送到客户端显示。因此,最好从数据库读出已排好序的树。
我们知道,字符串排序是按照字典序形式。结合SQL 语句的特点和树结构特点,数据库表中,节点的类别代码采用多级字符串形式,如AAABBBCCC,从树根节点开始,每向下一级字符串就增加一级,并且子节点类别代码以父节点类别代码开始,再开始本级的类别代码。同级的节点按照生成的顺序编号,如节点类别代码为AAA 的下一级孩子类别代码为AAAAAA,AAAAAB 等,AAAAAB 的孩子节点为AAAAABAAA、AAAAABAAB等。每一级编号字符的宽度与实际的应用关联,如AAA~ZZZ 一级则有263 个节点,如果不够用再增加一个字符用于编码。该巧妙的编号方式。使得在执行SQL 语句select * from tree_class order by classcode 后,一次获得完整的先序树。
2.3 业务逻辑层设计
2.3.1 动态加载技术
如果一次性获取完整的先序树,构造成xml提供给JavaScript解析,数据量越大,消耗的资源越多,客户端响应延迟时间就越长,因此对于大数据量的树,采用动态加载方式,即每次单击“+”图片时,判断是否已加载子节点数据,如果未加载则通过Ajax的XMLHTTP组件XMLHTTPRequest对象异步发送请求,连接服务器执行SQL 语句“select * from tree_class where parent = ?order by classcode ”获取节点数据。相关JavaScript 代码如下:
if((node.childNodes[i].nodeType==1)&&(node.childNodes[i].tagName == "leaf")){ var name=node.childNodes[i].getAttribute("text"); ………… var temp=dhtmlObject.a0Find(parentId);//获取父节点对象 temp.XMLload=1;//已加载 //构造html输出节点 dhtmlObject.insertItem(parentId,cId,name,im0,im1,im2,chd); dhtmlObject.addDragger = this;//设置可拖放的对象 }; } 2.3.3 树型结构的维护
在维护树型结构表时,删除节点较为简单,SQL 语句为: "delete from tree_class where classcode like′"+ classcode +"%′",即可将其节点和孩子一并删除;增加节点时,分为前插、后插、和插入子节点三种情况,前两种情况需要更新递归更新类别代码,后者只需找到父节点的孩子的最大类别代码加1 后,作为增加节点的类别代码;通过拖放来改变树的结构时,只需将拖动节点的parentId更新为目标节点的Classid即可,对应的SQL语句为:"update tree_class set parentId = "+ classidTo+" where classid = "+ classidFrom。
3、效率分析
对于树的存储一般有两种形式:二维表和链表,遍历方式一般也有深度遍历和广度遍历两种方式,遍历的时间复杂度都是O( n )。用二维表存储时,在内存中用数组的下标能准确定位节点的父节点、兄弟节点所在的数组下标。数据库中节点的定位也是准确的,但是将节点信息从数据库中读到内存中时,如果无法通过内存数组下标定位节点信息,那么就必须遍历一遍寻找一个节点,n 个节点中寻找一个节点的时间是O(n/2),n 个节点排序的时间复杂度将是O( n2/2),这也是一般实现的B/S 模式的树结构效率低下的原因。本方案采用字典序编号方案,使得从数据库中取得的树是已经排序的,直接遍历生成客户页面程序,时间复杂度为O( n )。















 注:本站部分文章源于互联网,版权归原作者所有!如有侵权,请原作者与本站联系,本站将立即删除! 本站文章除特别注明外均可转载,但需注明出处! [MinTao学以致用网]
注:本站部分文章源于互联网,版权归原作者所有!如有侵权,请原作者与本站联系,本站将立即删除! 本站文章除特别注明外均可转载,但需注明出处! [MinTao学以致用网] 









